randomForest 패키지에서 10-fold Cross-validation으로 학습을 하려고 했다.
처음에는 다음과 같이 createFolds함수를 사용해서 train과 validation을 나누어서 분석을 진행하였다.
## 모델 학습(randomForest 사용)
# 교차 검증을 10번 진행
set.seed(54321)
k_fold<- createFolds(final2$activity, k=10, list=TRUE, returnTrain = FALSE)
for(i in 1:length(k_fold)) {
valid_index <- k_fold[[i]]
valid_set <- final2[valid_index,]
train_set <- final2[-valid_index,]
# Decision Tree 모델 생성
rf_model <- randomForest(as.factor(train_set$activity) ~ ., data = train_set, type="response")
# predict
rf_pred <- predict(rf_model, newdata = valid_set)
# fold별 모델 객체 생성
assign(paste0("fold_",i),rf_model)
# fold별 정확도 객체 생성
assign(paste0("accuracy_",i),sum(rf_pred == valid_set$activity) / NROW(valid_set$activity))
}
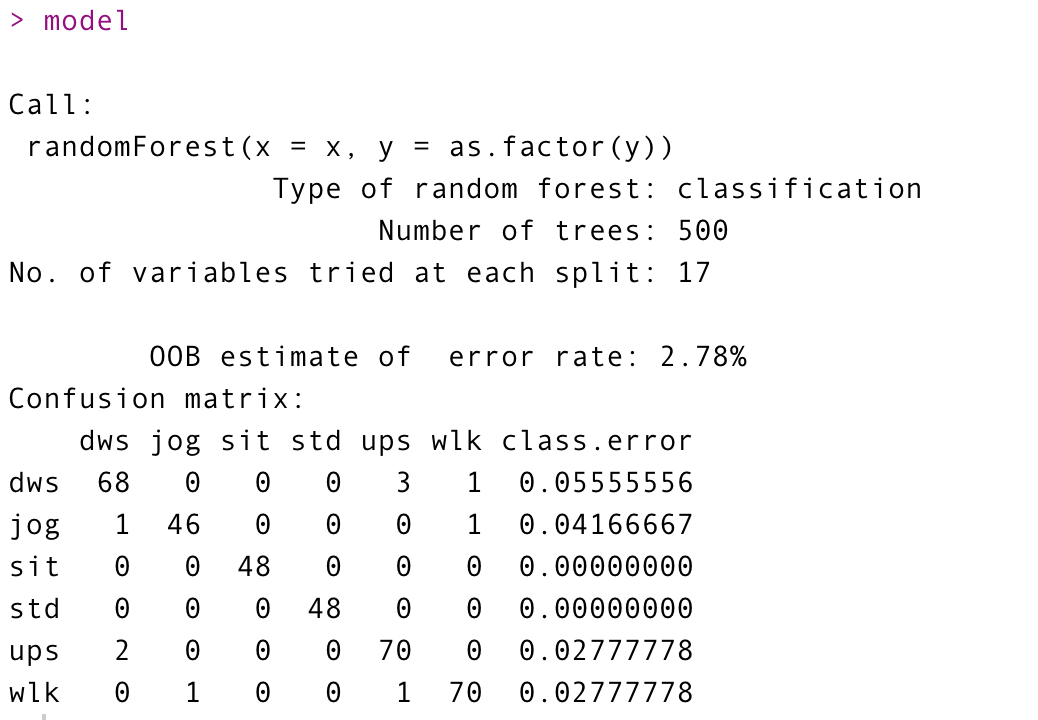
하지만, randomForest 패키지에서는 다음과 같이 하면 안된다.!! 교수님 말씀을 통해 처음 알게된 부분이었다.
randomForest로 학습을 하면 다음과 같이 OOB를 출력해 준다. 이 OOB(Out of Bag estimate of error rate)에러는 모델 훈련에 사용되지 않은 데이터를 사용한 에러 추정치를 의미한다.
모델 훈련에 사용되지 않은 데이터로 추정을 자동으로 해주기 때문에 validation set과 비슷한 의미를 가지게 된다. 그래서 위와 같은 코드로 분석을 하게되면 test set으로 추정한 느낌이라고 할 수 있다.
그래서 따로 데이터셋을 구분할 필요 없이 전체 데이터를 넣어줘야 하는 것이었다. randomForest 함수는 랜덤으로 데이터를 학습 시키기 때문에 전체 데이터로 10번을 돌리면 10-fold의 의미와 비슷은 하지만 정확하게 10-fold의 의미 라고는 할 수 없었다.
그래서 구글링을 통해 randomForest 패키지에도 cross validation을 할 수 있는 함수가 존재하다는 것을 알게 되었다. 역시 구글은 똑똑하다..ㅎㅎ
그 함수가 바로 rfcv 이다.
rfcv

사용 방법은 다음과 같다. cv.fold 파라미터로 fold수를 정할 수 있다!! 궁금해서 바로 사용해봤다.
rfcv() 함수는 먼저, 데이터셋의 모든 예측 변수를 사용해서 생성되며 예측 변수는 지니 중요도에 의해 정렬되며 모형에 대한 오류율은 추정된다.
다음으로 지니 중요도 순위 상위 50%에 속하는 예측 변수로 새 모델이 생성이 되는 방식이다. 이 과정을 계속해서 반복한다.
내가 사용한 데이터는 총 변수가 300개이기 때문에 먼저 300개로 예측을 한 후, 지니 중요도 순위로 상위 50%에 변수인 150개로 모델을 생성한다. 다음은 75개, 38, ... 1까지 모델을 생성한다.
model<-rfcv(x, as.factor(y), cv.fold = 10, trees = 500)
다음과 같이 모델을 생성하게 되면 3가지의 값을 제공한다. 조금 특이한? 값들을 제공한다.
1. n.var
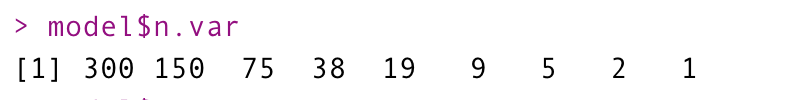
각 단계에서 사용되는 변수 수의 벡터를 의미한다.
2. error.cv

각 단계에 해당하는 에러값을 의미한다.
3. predicted
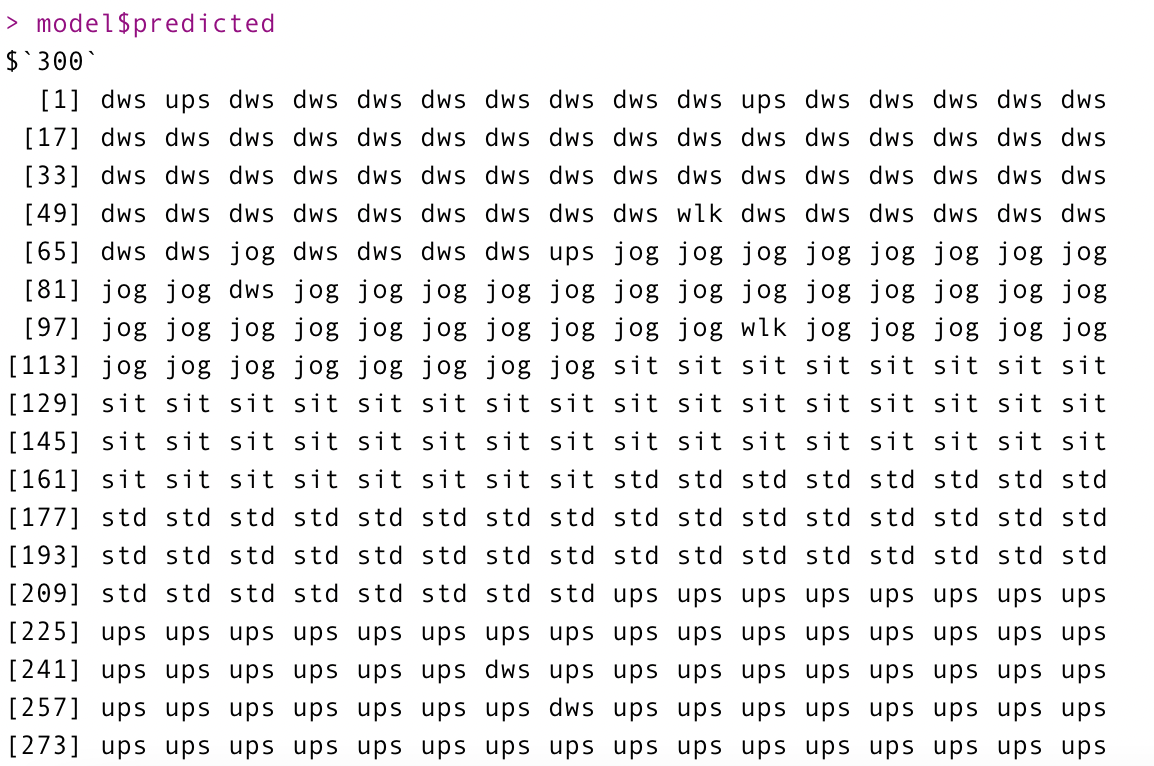
각 단계에서 실제로 예측한 값들을 의미한다.
보기 편하기 위해 각 단계에 해당하는 에러값에 대한 시각화를 진행해 보자.
with(model, plot(n.var, error.cv, log="x", type="o", lwd=2))
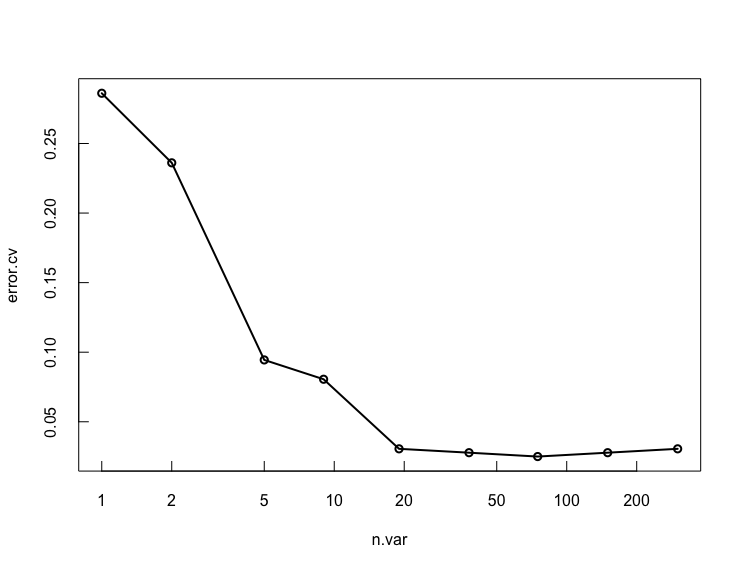
전체 변수를 사용했을때보다 그 다음, 다음 단계인 75개의 변수들을 사용했을때 에러값이 가장 작은것을 알 수 있다. 이렇게 그래프를 보고 에러값이 가장 작은 단계를 선택해서 예측하면 가장 좋은 결과를 얻을 수 있겠다.
한번 실제 데이터의 값과 비교해보도록 하자.
val_75 = model$predicted$`75` actul = as.factor(y) caret::confusionMatrix(val_75, actul)
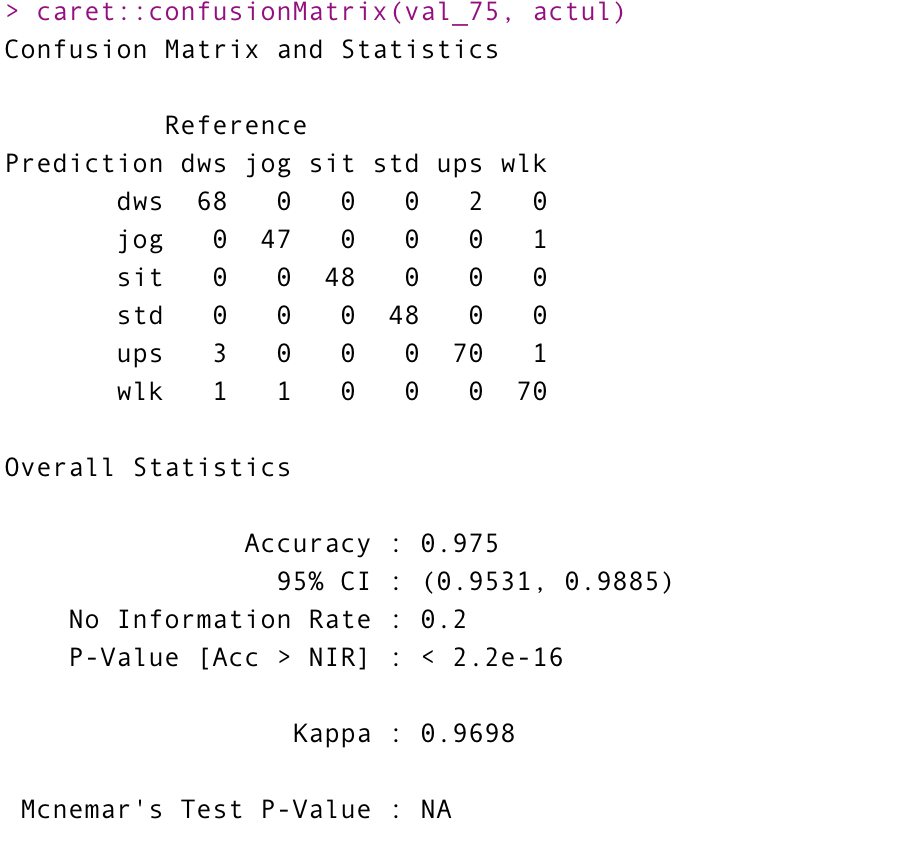
약 98%가 나왔다.
randomForest 패키지에도 cross validation이 있었다. 없을 줄 알았는데 역시 뭐든 찾아보는게 짱! 구글링이 답이다.
참고)
thebook.io/006723/ch10/03/04/01/
R을 이용한 데이터 처리 & 분석 실무: 랜덤 포레스트를 사용한 모델링
thebook.io
cran.r-project.org/web/packages/randomForest/randomForest.pdf
'Machine Learning' 카테고리의 다른 글
| 클러스터링에서 기억할 내용 (0) | 2021.09.28 |
|---|---|
| 비지도 학습 (0) | 2021.09.26 |
| 머신러닝 춤 (0) | 2021.03.02 |
| TF-IDF란? (0) | 2021.01.21 |
| 특이값 분해(Singular Value Decomposition, SVD) (0) | 2020.08.11 |
