분산이 어떻게 측정이 되는지 알아보도록 하자.
데이터의 퍼져 있는 양상을 어떻게 표현할 수 있을까? 가장 간단한 방법은 range함수를 이용하여 범위를 구하는 것이다.
y<- c(13,7,5,12,9,15,6,11,9,7,12)
range(y)
plot(1:11, y, ylim = c(0,20), pch=16, col="blue")
lines(c(4.5,4.5),c(5,15),col="brown")
lines(c(4.5,3.5),c(5,5),col="brown", lty=2)
lines(c(4.5,5.5),c(15,15),col="brown", lty=2)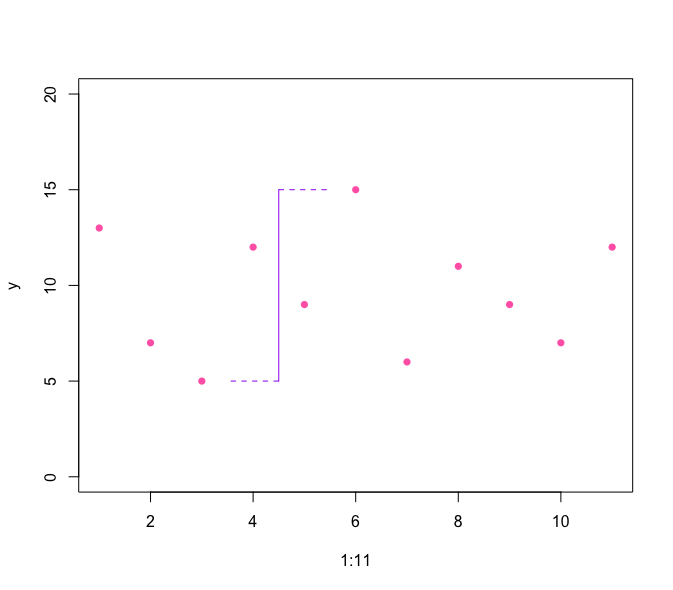
어느 정도 파악은 가능하지만 이상치에 큰 영향을 받는다는 단점이 존재한다. 모든 데이터를 고려하여 방법으로 변동성을 파악하는 편이 더 좋다.
먼저, 평균과 각 데이터 사이의 거리(잔차, 편차)를 살펴보자.
plot(1:11, y, ylim = c(0,20), pch=16, col="hot pink")
abline(h=mean(y), col='black')
for(i in 1:11) lines(c(i,i), c(mean(y), y[i]), col="purple")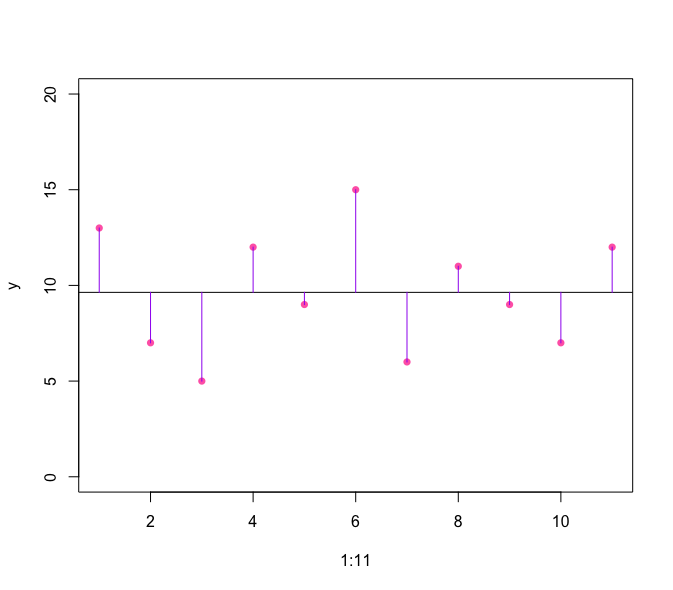
보라색 선이 길수록 변동성이 큼을 의미한다. 보라색의 길이를 모두 합한다면?? 음수의 값이 양수의 영향을 주기 때문에 좋은 지표는 아니다. 그렇다면 절댓값을 적용해서 더한다면? 좋은 지표라고 생각할 수 있지만 절댓값이 들어가게 되면 미분이 불가능한 부분이 생길 수도 있어 이론적인 전개가 쉽지 않다고 한다.
이러한 이유로 나온 척도가 잔차를 더하기 전에 제곱한 즉 잔차의 제곱합이다.
계산식은 다음과 같다.
sum((y - mean(y))^2)
자유도
자유도는 알 수 없는 모집단 모수의 값을 추정하고 이러한 추정치의 변동성을 계산할 때 사용 가능한 즉 데이터가 제공하는 정보의 양을 의미한다. 예제로 이해를 해보자.
다섯 개의 숫자의 표본이 있고 이 표본의 평균이 4라고 한다면 우리는 다섯 개의 합이 20이라고 말할 수 있다.
다섯 개의 숫자 중 우리는 아무거나 대입을 할 수 있다. 먼저 첫 번째 값에 2를 넣어보자. 다음으로 두 번째 값에 7을 넣고, 세 번째 값에 4를 넣고, 네 번째 값에 0을 넣었다고 해보자. 마지막으로 다섯 번째 값은 우리는 선택의 여지없이 7을 넣어야 한다. 조건에서 합이 20이라고 했기 때문이다.
우리는 첫번째 값에서 네 번째 값 까지는 자유롭게 선택할 수 있었다. 하지만 마지막 숫자는 선택의 여지가 없었다. 그래서 이때의 자유도는 4라고 말할 수 있다.
일반적으로 표본 크기가 n인 경우 평균을 추정할 때 n-1의 자유도를 갖는다.
위에서 제곱합이 변동성을 측정하기 좋은 추정 값이라고 언급했다. 그런데 데이터의 크기가 커지게 되면 제곱합도 커지게 되는 일이 발생한다. 그래서 표본의 크기를 나누어서 편차를 구해보자.
$$\sum_{k=1}^n\left(X_k-\bar{X}\right)^2 $$
그런데 다음 제곱합 공식을 샬펴보면 표본 평균을 모른다면 계산을 할 수가 없다. 즉 우리는 이 값을 계산해야 한다. 표본 평균은 데이터로부터 추정해야 하는 모수이다. 그렇기 때문에 자유도를 하나 잃어버리게 된다. 그래서 우리는 평균 제곱 편차를 계산할 때 표본의 크기 n이 아닌 n-1로 제곱합을 나눠서 계산을 해야 한다.
$$s^2 = \frac{1}{n-1}\sum_{k=1}^n{\left(X_k-\bar{X}\right)^2}$$
다음식을 R 코드로 표현하여 계산해보도록 하자.
variance<- function(x) sum((x-mean(x))^2)/(length(x)-1)
variance(y)
[1] 10.25455다음과 같이 직접 함수로 만들어서 계산을 해도 좋지만 R에서는 이미 var라는 함수를 통해 분산을 계산하도록 제공하고 있습니다.
var(y)
[1] 10.25455값을 비교해보면 동일하게 나옴을 확인하였습니다.
참고
크롤리의 통계학 강의
'Statistics' 카테고리의 다른 글
| Leverage vs Influence (0) | 2021.09.12 |
|---|---|
| 좋은 선형 회귀 모델이란?? (0) | 2021.09.04 |
| 중심 경향(central tendency) (0) | 2021.03.30 |
| 통계에서 말하는 로버스트하다? (0) | 2021.02.08 |
| 다중공선성(Multicollinearity) (0) | 2020.11.12 |


