캐글에서 제공하는 자전거 대여수요 데이터를 사용해서 선형 회귀와 트리 기반 회귀를 비교해 가며 공부를 해보겠습니다.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inlinebike_df = pd.read_csv("./bike_train.csv")
bike_df.head()
bike_df.info()
데이터를 살펴보면 NULL 데이터는 없으며 대부분 int와 float 숫자형이고 datetime 컬럼은 object형을 가지고 있습니다.
datetime 칼럼을 년, 월, 일, 시간으로 분리하도록 하겠습니다. 그렇기 위해서는 먼저 문자열을 datetime 타입으로 변경을 해주고 apply 사용해 적용해보도록 하겠습니다.
bike_df['datetime'] = bike_df.datetime.apply(pd.to_datetime)
bike_df['year'] = bike_df.datetime.apply(lambda x : x.year)
bike_df['month'] = bike_df.datetime.apply(lambda x : x.month)
bike_df['day'] = bike_df.datetime.apply(lambda x : x.day)
bike_df['hour'] = bike_df.datetime.apply(lambda x : x.hour)
bike_df.head(3)
새로운 칼럼들이 추가된것을 확인하였습니다. 이제 datetime 컬럼은 삭제하도록 하겠습니다.
또한 casual+registered = count 이기 때문에 두 칼럼을 삭제하도록 하겠습니다.
bike_df.drop(['datetime','casual','registered'],axis=1, inplace=True)
bike_df.head(3)
회귀 모델을 평가하는 방법은 종류가 다양합니다. 여기서는 RMSLE (Root Mean Squared Log Error), MAE (Mean Absolue Error), RMSE (Root Mean Squared Error)을 사용하겠습니다.
그런데 사이킷런에서는 RMSLE를 따로 제공하지 않습니다. 그래서 따로 log 사용해서 만들어 보도록 하겠습니다.
$$ RMSLE= \sqrt{\frac{1}{n}\sum_{i=1}^{n}(log(y_{i}+1)-log(y\hat{}_{i}+1))^2}$$
from sklearn.metrics import mean_squared_error, mean_absolute_error
def rmsle(y,pred):
log_y = np.log1p(y)
log_pred = np.log1p(pred)
squared_error = (log_y - log_pred)**2
rmsle = np.sqrt(np.mean(squared_error))
return rmsleMAE와 RMSE는 mean_squared_error을 사용해서 구할 수 있습니다.
이제 모델을 적용시키겠습니다. 사이킷런의 LinearRegression을 사용하도록 하겠습니다.
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LinearRegression, Ridge, Lasso
y_target = bike_df['count']
x_features = bike_df.drop(['count'],axis=1, inplace=False)
x_train, x_test, y_train, y_test = train_test_split(x_features, y_target, test_size=0.3, random_state=0)
lr_reg = LinearRegression()
lr_reg.fit(x_train,y_train)
pred =lr_reg.predict(x_test)
evaluate(y_test,pred)evalute는 RMSLE, RMSE, MAE의 성능 평가가 모두 포함되어 있는 함수입니다.
RMSLE:1.165, RMSE:140.900, MAE:105.924결과가 다음과 같이 나왔습니다. 비교적으로 오류값이 크게 나왔습니다.
모델의 Target값의 분포도를 한번 살펴보도록 하겠습니다.
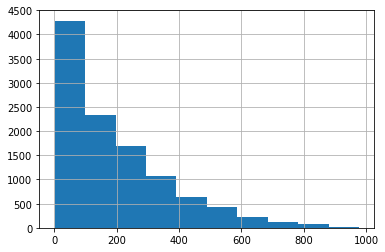
그래프를 보면 정규분포의 형태를 이루지 않게 되어있습니다. 0~200에서 많이 분포되어 데이터가 왜곡되어 있음을 알 수 있습니다. 이렇게 왜곡된 형태는 로그를 적용해 변환을 해주는 것이 필요합니다.
여기서 주의!! 해야할 부분은 테스트의 적용을 할때는 다시 원래 상태로 돌려서 적용을 해주어야 합니다!!
y_log_tf = np.log1p(y_target)
y_log_tf.hist()
로그 변환 결과 어느정도 왜곡 정도가 많이 향상 되어있습니다. 이 데이터를 통해서 다시 학습을 해보도록 하겠습니다.
y_target_log = np.log1p(y_target)
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LinearRegression, Ridge, Lasso
y_target = bike_df['count']
x_features = bike_df.drop(['count'],axis=1, inplace=False)
x_train, x_test, y_train, y_test = train_test_split(x_features, y_target_log, test_size=0.3, random_state=0)
lr_reg = LinearRegression()
lr_reg.fit(x_train,y_train)
pred =lr_reg.predict(x_test)
y_test_exp = np.expm1(y_test)
pred_exp = np.expm1(pred)
evaluate(y_test_exp,pred_exp)RMSLE:1.017, RMSE:162.594, MAE:109.286결과를 보면 이전에 비해 RMSLE 는 줄었지만 RMSE는 늘었습니다.
왜 이런 결과가 나왔을까요??
한번 피처들의 회귀 계수 값을 확인해 보도록 하겠습니다!!
coef = pd.Series(lr_reg.coef_, index = x_features.columns)
coef_sort = coef.sort_values(ascending=False)
sns.barplot(x=coef_sort.values, y=coef_sort.index)
데이터를 보면 Year 피처의 값이 유독 큰 값을 가지고 있습니다. Year은 연도를 의미하기 때문에 카테고리형 이지만 숫자형 값으로 입력되어 있습니다.
이러한 숫자형 카테고리 값을 선형 회귀에 사용할 경우 회귀 계수를 연살할 때 이 숫자형 값에 크게 영향을 받는 경우가 발생합니다. 그래서 이러한 피처들을 원-핫 인코딩을 적용하여 변화을 해주어야 합니다.
판다스에서 제공하는 get_dummies()를 사용해서 컬럼들을 모두 원=핫 인코딩을 하여 다시 성능을 평가해보도록 하겠습니다.
x_features_onehot = pd.get_dummies(x_features, columns=['year','month','hour','holiday','workingday','season','weather'])x_train, x_test, y_train, y_test = train_test_split(x_features_onehot, y_target_log, test_size=0.3, random_state=0)def get_model_predict(model, x_train, x_test, y_train, y_test, is_expm1=False):
model.fit(x_train, y_train)
pred = model.predict(x_test)
if is_expm1:
y_test = np.expm1(y_test)
pred = np.expm1(pred)
print('***',model.__class__.__name__,'***')
evaluate(y_test,pred)
lr_reg = LinearRegression()
ridge_reg = Ridge(alpha=10)
lasso_reg = Lasso(alpha=0.01)
for model in [lr_reg, ridge_reg, lasso_reg]:
get_model_predict(model,x_train,x_test,y_train, y_test, is_expm1=True)*** LinearRegression ***
RMSLE:0.589, RMSE:97.484, MAE:63.106
*** Ridge ***
RMSLE:0.589, RMSE:98.407, MAE:63.648
*** Lasso ***
RMSLE:0.634, RMSE:113.031, MAE:72.658결과를 보면 성능이 많이 향상된것을 알 수 있습니다.
Reference
'Machine Learning' 카테고리의 다른 글
| 차원 축소(Dimension Reduction) (0) | 2020.06.17 |
|---|---|
| 회귀 실습 - (자전거 대여 수요 예측) (0) | 2020.05.28 |
| 회귀 평가 지표 (0) | 2020.05.27 |
| 로지스틱 회귀 (2) | 2020.05.27 |
| 규제 선형 모델 (0) | 2020.05.27 |

