LightGBM은 XGBoost와 같이 부스팅 알고리즘에서 가장 주목을 받고 있습니다. XGBoost는 매우 뛰어나지만 아지까진 학습 시간이 오래 걸린다는것이 큰 단점입니다.
LightGBM 장단점
1. LightGBM 장점
학습하는데 걸리는 시간이 적다.
메모리 사용량이 상대적으로 적은편이다.
- 카테고리형 피처들의 자동 변환과 최적 분할
2. LightGBM 단점
적은 데이터 세트의 적용을 할 경우 과적합 가능성이 크다.(일반적으로 적은 데이터 세트의 기준은 공식 문서에서 10,000건 이하로 정의)
LightGBM 특징
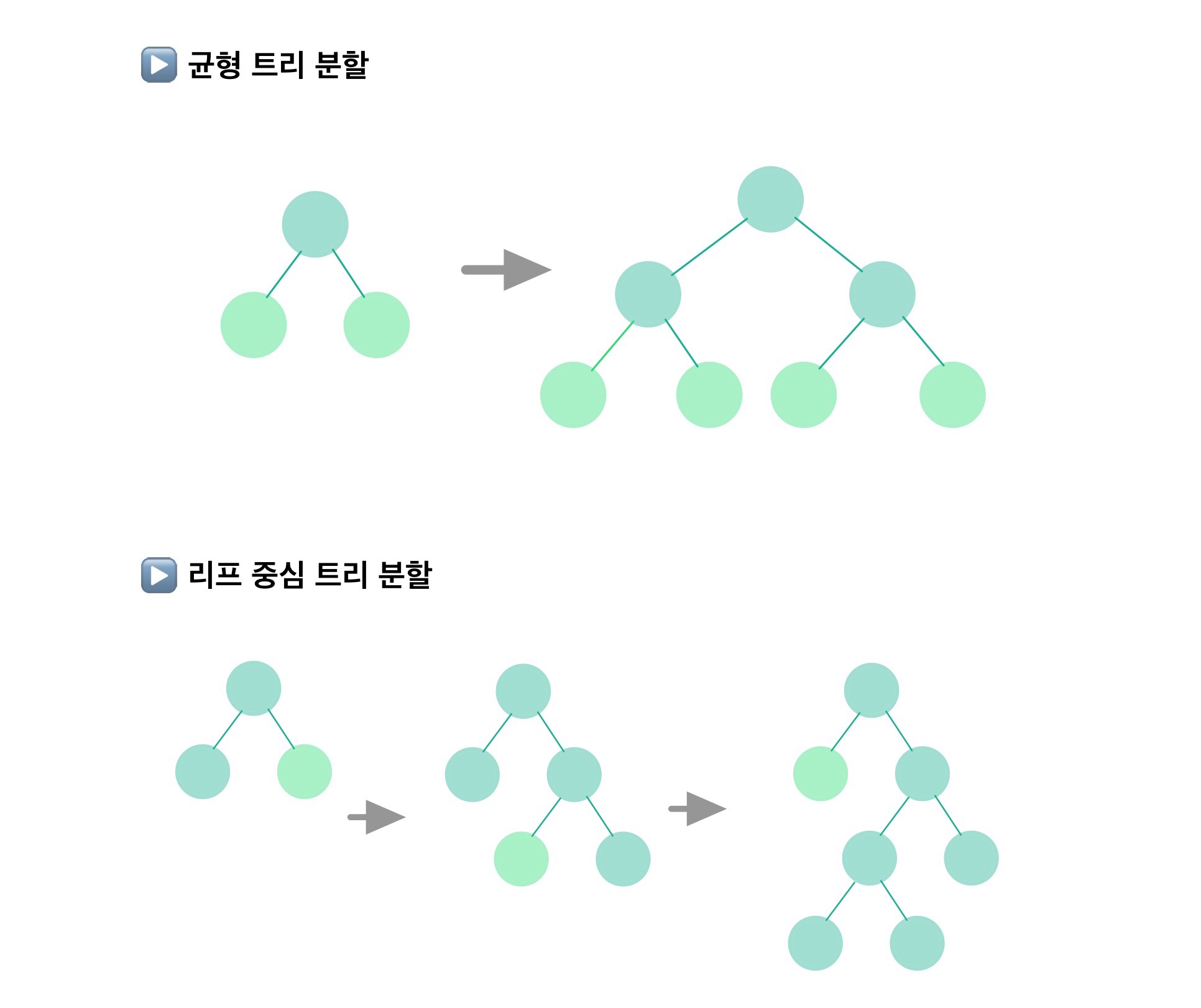
LightGBM은 리프 중심 트리 분할(Leaf Wise) 방식을 사용합니다. 기존의 트리 기반 알고리즘은 균형 트리 분할(Level Wise) 방식을 사용합니다. 풀어서 설명하자면 최대한 균형이 잡힌 트리를 유지하면서 분할하기 때문에 트리의 깊이가 최소화가 될 수 있습니다. 반대로 균형을 맞추기 위한 시간이 필요하다는 단점이 존재합니다.
하지만 LightGBM의 리프 중심 트리 분할은 트리의 균형을 맞추지 않고 최대 손실 값(Max data loss)을 가지는 리프 노트를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 트리가 생성됩니다. 그런데 최대 손실값을 가지는 리프 노드를 반복할수록 결국은 균형 트리의 분할 방식보다 예측 오류 손실을 최소화 할 수 있습니다.
LightGBM 하이퍼 파라미터
| 파라미터 명 | 기본 값 | 설명 |
| num_iterations | 100 | 반복 수행하려는 트리의 개수를 지정합니다. 너무 크게 설정하면 과적합이 발생합니다. |
| learning_rate | 0.1 | 부스팅 스텝을 반복적으로 수행할 때 업데이트 되는 학습률입니다. 0~1 사이의 값을 지정합니다. |
| max_depth | 1 | 트리 기반 알고리즘의 max_depth와 같은 역할입니다. 만약 0보다 작은 값을 입력하면 깊이에 제한이 없습니다. |
| min_data_in_leaf | 20 | 의사결정 나무의 min_samples_leaf와 같은 파라미터입니다. 과적합을 제어해주는 파라미터로 사용됩니다. |
| num_leaves | 3 | 하나의 트리가 가질 수 있는 최대 리프 개수를 의미합니다. |
| boosting | gbdt | |
| bagging_fraction | 1.0 | 데이터를 샘플링하는 비율을 지정합니다 과적합을 제어하기 위해 사용됩니다. |
| feature_fraction | 1.0 | 개별 트리를 학습할 때 무작위로 선택하는 피처의 비율입니다. |
| lambda_l1 | 0.0 | L1 regulation 제어를 위한 값입니다. |
| lambda_l2 | 0.0 | L2 regulation 제어를 위한 값입니다. |
☆ 하이퍼 파라미터 튜닝 방안
- num_leaves 개수를 높이면 정확도가 높아지지만, 트리의 깊이가 깊어지고 모델이 복잡해져 결국은 과적합 발생 가능성이 커집니다.
- min_data_in_leaf 은 과적합을 위한 중요 파라미터입니다. num_leaves와 학습 데이터의 크기에 따라 달라지겠지만 일반적으로 큰 값을 설정하게 되면 트리가 깊어지는 것을 방지해 줍니다.
- max_depth는 깊이의 크기를 제한합니다. 위 두개의 파라미터들과 결합해서 과적합을 개선해 줍니다.
LightGBM 실습
앞의 포스팅에서 계속 사용했었던 유방암 데이터 세트를 사용해서 실습을 해보겠습니다.
LightBGM도 조기 중단을 할 수 있습니다. XGBClassifier와 동일하게 fit()에 파라미터를 설정해주면 됩니다.
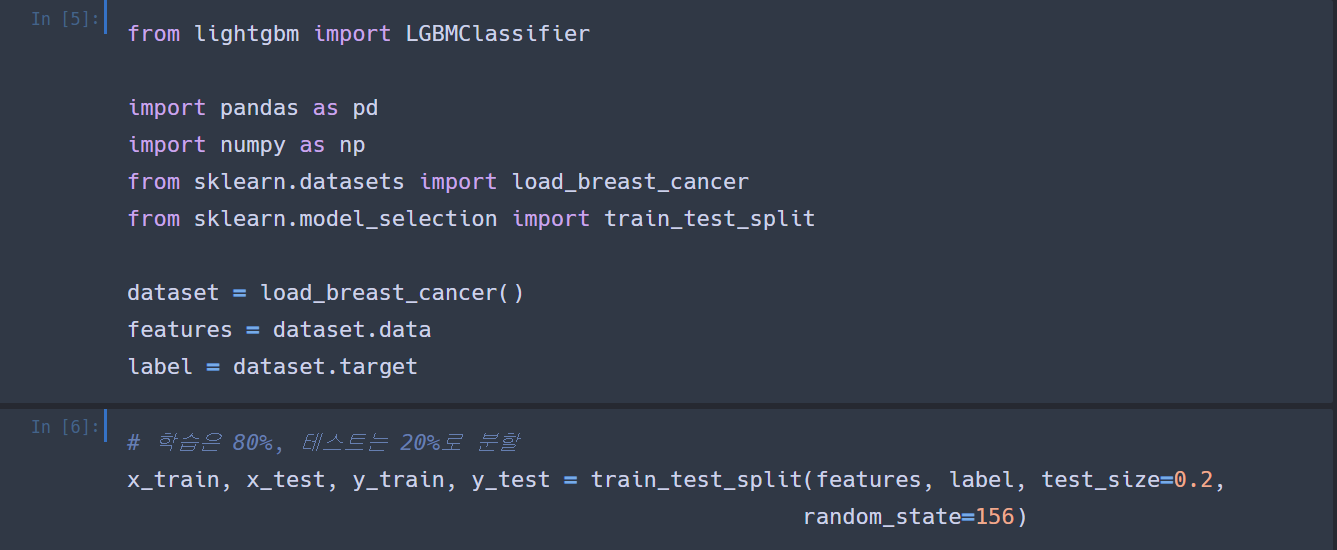
필요한 모듈과 데이터를 불러오고 학습 비율을 80%, 테스트 비율을 20%로 데이터를 분할하겠습니다.
앞의 XGBoost 예제와 동일하게 n_stimators는 400으로 설정을 하고 조기 중단도 수행하겠습니다.

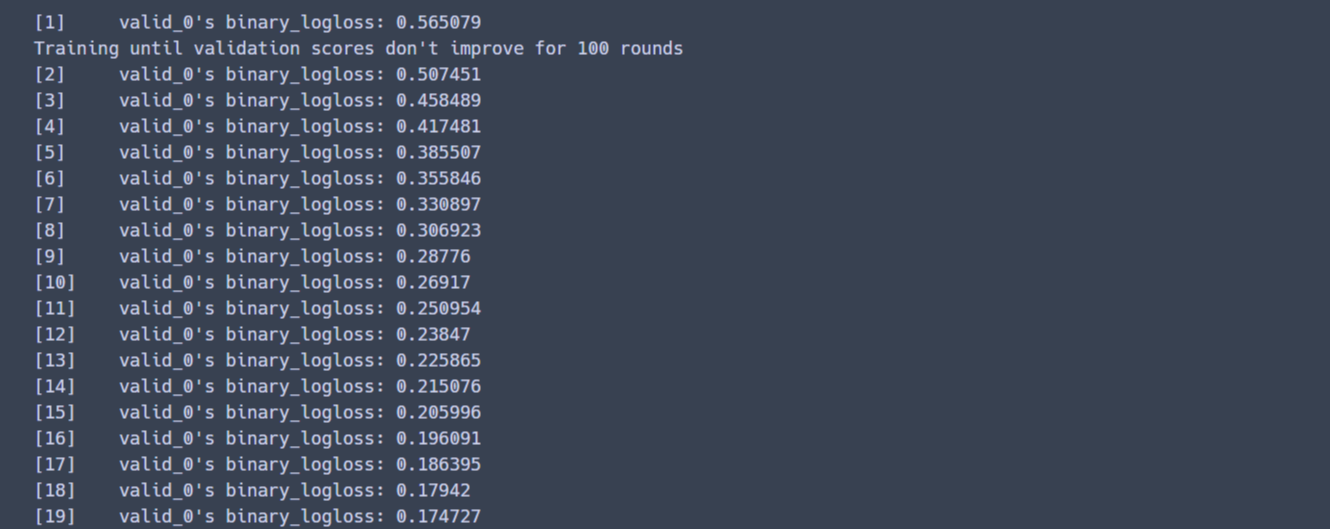

* 조기 중단을 147번 까지 수행하고 학습을 종료하였습니다.
다음은 예측 성능 평가를 해보도록 하겠습니다.

* 정확도가 약 94.74% 정도 나왓습니다. 앞의 예제보다 성능이 약하지만 학습 데이터와 테스트 데이터의 크기가 작아서 두 알고리즘간의 성능 비교는 크게 의미가 없습니다.
LightGBM 실습 시각화

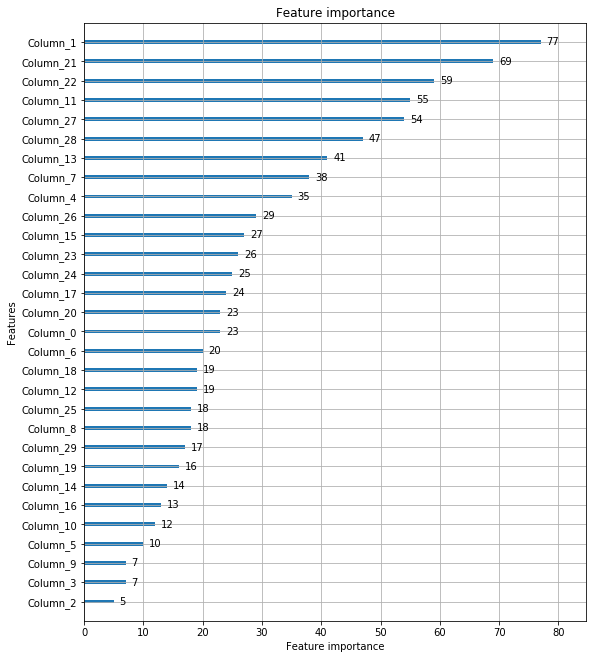
* Column_0은 첫 번째 피처, Column_1은 두 번째 피처를 의미합니다.
Reference
'Machine Learning' 카테고리의 다른 글
| K-NN 알고리즘 (0) | 2020.05.05 |
|---|---|
| 분류 실습(신용카드 사기 데이터) (0) | 2020.05.03 |
| XGBoost 실습 - 사이킷런 래퍼 - (0) | 2020.04.27 |
| XGBoost 실습 - 파이썬 래퍼 - (0) | 2020.04.27 |
| XGBoost(eXtra Gradient Boost) (0) | 2020.04.26 |



