머신러닝 모델을 평가하기 위한 여러 가지 방법들이 존재합니다. 일반적으로는 크게 분류인지? 회귀인지?에 따라서 나누어지게 됩니다.
먼저 분류의 성능 평가 지표에 대해서 알아보도록 하겠습니다.
정확도
정확도(Accuracy)는 실제 데이터에서 예측한 데이터가 얼마나 동일한가를 판단해주는 지표입니다.

정확도는 특히 이진 분류의 경우 데이터의 구성 정도 에 따라서 모델의 성능을 왜곡할 가능성이 있습니다. 그렇기 때문에 정확도 하나만 가지고는 성능을 평가하면 안됩니다.
특히 정확도는 불균형한 레이블을 가지는 모델의 성능을 평가할 경우 적합하지 못한 평가 방법입니다. 예를 들어서 100개의 데이터 중 90개의 데이터의 레이블이 0, 10개의 데이터 레이블이 1이라고 했을때 무조근 그냥 0으로 예측 결과를 나타내주는 모델이 있다고 해도 정확도가 90%이 됩니다.
예제 데이터를 사용해서 확인해 보도록 하겠습니다. 사용 데이터는 MNIST 데이터로 숫자 이미지의 펙셀 정보를 가지는 데이터 입니다. 이 데이터를 10%를 True, 90%를 False를 가지는 불균형한 데이터로 변형을 하였습니다.
그리고 다음 코드를 사용해서 데이터를 모두 0으로 예측하도록 하겠습니다.
class MyFakeClassifier(BaseEstimator):
def fit(self, X, y):
pass
def predict(self,X):
return np.zeros((len(X),1),dtype=bool)print(pd.Series(y_test).value_counts())0 405
1 45
dtype: int64테스트 데이터 레이블의 분포도를 확인하였습니다.
정확도를 측정할때 사용되는 함수는 accuracy_score입니다.
fakeclf = MyFakeClassifier()
fakeclf.fit(X_train, y_train)
fakepred = fakeclf.predict(X_test)
print(accuracy_score(y_test,fakepred))0.9모두 0으로 예측해도 정확도 90%가 결과가 나오게 됩니다. 이렇게 정확도는 불균형한 레이블 데이터에서 사용을 하기에는 적합하지 못합니다. 그래서 분류 평가 지표에서는 이러한 문제점을 개선하기 위해서 여러가지 지표들을 결합해서 평가해야 합니다. 다음 평가 지표에 대해서 알아보도록 하겠습니다.
오차 행렬
오차행렬(confunsion matrix)은 혼동행렬이라고도 부릅니다. 이 지표는 분류 모델이 얼마나 confused 한지를 함께 제공해주는 지표입니다. 다시 말하자면 어떠한 종류의 예측 오류가 존재하는지를 알려줍니다.
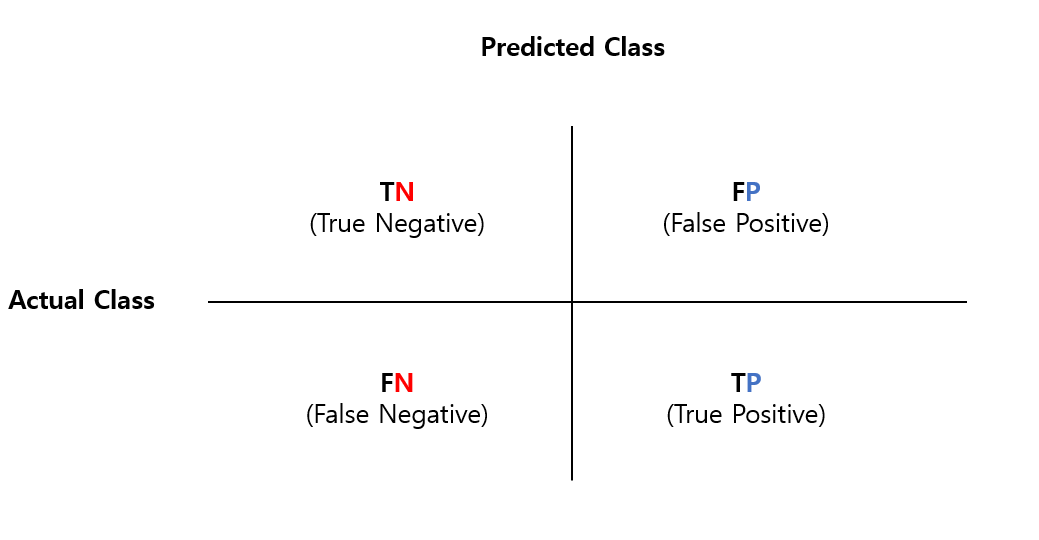
오차 행렬을 위 그림과 같이 4분면으로 생겼습니다. 4분면에서 왼쪽 오른쪽을 예측이 된 클래스 값을 기준으로 Negative와 Postive로 분류하고 위 아래를 실제 클래스 값을 기준으로 Negative와 Positive로 분류합니다.
공부를 하면서 오차 행렬을 하는데 어려움이 많았는데 한번 차근차근 정리를 하며 설명을 해보도록 하겠습니다.
먼저 TN은 True Negative 입니다. True는 예측 클래스의 값과 실제 클래스 값이 같다는 의미이고 Negative는 예측값이 Negative 값이라는 의미입니다. 다시 정리를 하자면 TN은 예측을 Negative로 예측했는데 실제 값도 Negative 값이라는 의미입니다.
쉽게 설명을 하자면 True&False는 예측값과 실제값이 동일한가/틀린가를 의미하고 Negative$Positive는 예측 결과값이 부정/긍정 인지를 의미한다고 생각하면 쉬워요!!
-
TN: 예측값을 Negative로 예측하고 실제 값도 Negative 값
-
FN: 예측값을 Negative로 예측하였지만 실제 값은 Positive 값
-
TP: 예측값을 Positive로 예측하고 실제 값도 Positive 값
-
FP: 예측값을 Positive로 예측하였지만 실제 값은 Negative 값
사이킷런에서는 오차 행렬을 사용하기 위해서 confusion_matrix()를 제공합니다. 앞의 예제를 한번 오차 행렬로 나타내보도록 하겠습니다.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test,fakepred)
array([[405, 0],
[ 45, 0]], dtype=int64)오!! 출력은 ndarray 형태로 출력이 됩니다!!
오차 행렬을 활용한 주요 지표들이 있습니다. 그것은 바로 정확도, 정밀도, 재현율 입니다.앞에서는 정확도를 설명하였습니다.
위 표를 활용해서 정확도를 구하려면
정확도 = (TN+TP)/(TN+FP+FN+TP) 의 수식으로 계산할 수 있습니다. 하지만 정확도는 단지 분류의 모델의 성능을 측정할 수 있는 한 가지 요소일뿐 이것만으로는 모델을 평가하기 어렵다고 앞의 예제를 통해 알아보았습니다. 다음으로 불균형한 분포에서 유용한 정밀도와 재현율에 대해서 알아보도록 하겠습니다.
정밀도&재현율
정밀도: 예측을 Positive로 한 값들 중에서 예측과 실제 값이 Positive로 일치하는 데이터의 비율을 의미합니다. 공식은 다음과 같습니다.
- 정밀도 = TP / (FP+TP)
분모인 (FP+TP)는 예측을 Positive로 한 데이터 수이고 분자 TP는 예측과 실제 값이 Positive로 일치하는 데이터 수를 의미합니다.
재현율: 실제 값이 Positive인 값들 중에서 예측과 실제 값이 Positive로 일치하는 데이터의 비율을 의미합니다. 공식은 다음과 같습니다.
- 재현율 = TP / (FN+TP)
분모인 (FN+TP)는 실제 값이 Positive인 데이터 수이고 분자 TP는 예측과 실제 값이 Positive로 일치하는 데이터 수를 의미합니다. 재현율은 똑같은 말로 민감도(Sensitivity) 라고도 불립니다.
정밀도와 재현율은 모델의 특성에 따라서 특정 평가 지표가 더 중요하게 작용을 하게 됩니다.
재현율은 실제 Positive 데이터를 Negative로 잘못 판단했을 경우 업무의 큰 영향을 미치게 되는 경우 중요하게 작용을 하게 되는데요.
예를들어 암을 판단해주는 모델의 경우 재현율이 중요한 성능 평가로 작용을 하게 됩니다. 실제 Positive인 암 환자를 Negative 음성으로 판단할 경우 최악의 경우 생명을 위협할 정도로 심각하기 때문입니다.
정밀도는 스팸메일의 여부를 판단하는 모델에서 중요하게 작용이 될것입니다. 실제 Positive인 스팸 메일을 Negative인 일반 메일로 분류를 하게 되면 메일을 받는 사람은 불편함을 느끼는 정도로 끝나지만 실제 Negative인 일반 메일을 Positive인 스팸 메일로 분류를 하게 되면 메일을 받지 못해 회사에 중요한 업무 관련 메일의 경우에는 큰 문제가 되기 때문입니다.
재현율과 정밀도는 서로 보완적인 지표로 많이 사용이 됩니다. 그렇기 때문에 모두 높은 수치를 얻는 것이 좋은 성능 평가가 될것입니다.
사이킷런에서는 정밀도는 precision_score(), 재현율은 recall_score()을 사용해서 구할 수 있습니다.
예제 데이터로 암 관련 데이터를 사용해서 성능 평가를 해보도록 하겠습니다. 데이터 전처리 및 모델 생성 부분은 생략하도록 하겠습니다.
from sklearn.metrics import precision_score, recall_score
print('정밀도:{:.3f}'.format(precision_score(y_test,pred)))
print('재현율:{:.3f}'.format(recall_score(y_test,pred)))정밀도:0.825
재현율:0.770
F1 스코어
F1 스코어는 정밀도와 재현율을 결합한 형태의 지표입니다. F1 스코어는 정밀도와 재현율이 어느 한쪽으로 치우치지 않는 형태일때 높은 값을 가지게 됩니다. 공식은 다음과 같습니다.
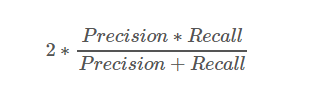
사이킷런에서는 F1 스코어를 구하기 위해서 f1_score()를 사용합니다.
from sklearn.metrics import f1_score
f1 = f1_score(y_test,pred)
print('F1 스코어:{0:.4f}'.format(f1))F1 스코어:0.7966
ROC곡선 & AUC
ROC곡선과 AUC 스코어는 이진 분류의 예측 성능을 측정하는데에서 중요하게 사용되는 지표입니다.
먼저 ROC곡선은 FPR(False Positive Rate)이 변할 때 TPR(True Positive Rate)이 어떻게 변화하는지를 나타내는 곡선입니다.
TPR은 재현율을 의미합니다. 다른 말로는 민감도라고도 불립니다. 이 민감도에 대응하는 TNR(True Negative Rate)인 특성이 있습니다.
- 민감도: 질병이 있는 사람은 질병이 있는것으로 양성 판정
- 특이성: 질병이 없는 사람은 질병이 없는 것으로 음성 판정
사이킷런은 ROC 곡선을 구하기 위해서 roc_curve()를 사용합니다. precision_recall_과 사용방식이 유사합니다.
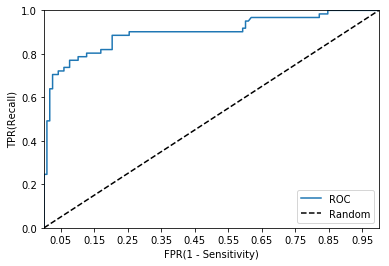
ROC 곡선은 FPR과 TPR의 변화하는 값을 보는데 이용하고 분류의 성능 평가로 사용을 할때는 ROC 곡선을 기반하는 AUC값으로 결정하게 됩니다. AUC 값은 ROC 곡선의 밑의 면적을 구하는 값으로 1에 가까울수록 좋은 수치입니다.
가운데 대각선 직선은 랜덤 수준의 이진 분류 AUC값으로 0.5입니다. 보통 분류는 0.5 이상의 AUC값을 가집니다.
Reference
'Machine Learning' 카테고리의 다른 글
| LinearRegression 실습( 주택 가격 예측) (0) | 2020.05.27 |
|---|---|
| 회귀란? (0) | 2020.05.26 |
| 의사결정 나무 실습 (0) | 2020.05.07 |
| K-NN 알고리즘 (0) | 2020.05.05 |
| 분류 실습(신용카드 사기 데이터) (0) | 2020.05.03 |



