bag of words
백오브워즈는 단어의 등장 순서에 관계없이 단어의 등장 빈도를 임베딩으로 쓰는 기법입니다.
문장을 단어들로 나누고 이들을 중복집합에 넣어서 임베딩으로 활용합니다.

가방에 넣고 흔들어서 빈도를 세어 본다고 생각해보세요!!
백오브워즈는 '저자가 생각하는 주제가 문서에서의 단어 사용에 녹아 있다' 는 가정이 깔려있습니다.
즉 주제가 비슷한 문서라면 단어의 빈도 또한 비슷하다는 이야기입니다.
단어-문서 행렬(Term-Document matrix)
단어 문서 행렬은 각 단어들의 빈도를 나타낸 표입니다. 행은 단어, 열은 문서에 대응합니다.
| 문서 1 | 문서 2 | 문서 3 | 문서 4 | |
| 딸기 | 0 | 2 | 8 | 6 |
| 복숭아 | 0 | 1 | 0 | 0 |
| 수박 | 0 | 1 | 0 | 0 |
예시로 다음과 같이 이루어져 있다고 한다면 문서3과 문서4의 관계가 높다고 생각할 수 있겠습니다앙.
백오브워즈는 정보검색 분야에서 많이 쓰인다고 합니다.
TF-IDF
단어의 빈도를 그대로 임베딩으로 쓰는 것에는 큰 문제가 있습니다.
예를들어 을/를, 이/가 같은 조사들은 문서에서 많이 등장하게 되는데 이것으로는 문서의 내용을 파악하기 어렵기 때문입니다.
이 부분을 보완하기 위해 제안된 것이 바로 TF-IDF(Term Frequency - Inverse Document Frequency)입니다.
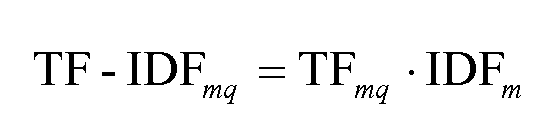
- TF: 문서에 단어가 얼마나 많이 등장했는가(빈도)
- DF: 특정 단어가 나타난 문서의 수
- IDF: 전체 문서수를 해당 단어의 DF로 나눔
Q. 여기서 IDF 값이 크다는 것은 무엇을 의미할까요??
특이하다!! 특이한 단어라는 뜻입니다.
Deep Averaging Network
Deep Averaging Network는 백오브워즈를 가정한 뉴럴 네트워크 버전입니다.

DAN과 백오브워즈 가정은 단어의 순서를 고려하지 않습니다.
문장 내에 어떠한 단어가 쓰였는지?? 얼마나 많이 쓰였는지 빈도만을 생각합니다.
Reference
1. https://patents.google.com/patent/KR20110095338A/ko
KR20110095338A - 검색 용어에 대한 인덱싱 가중치 할당 - Google Patents
보이스-대-텍스트 검색 인덱싱 서버(voice-to-text-search indexing server)(106)로서, 문서(300) 내의 검색 용어에 할당된 인덱싱 가중치(320)를 저장하도록 구성된 메모리 - 상기 문서(300)는 문서들의 수집물(3
patents.google.com
2. https://www.weak-learner.com/blog/2019/07/31/deep-averaging-networks/
3. 한국어 임베딩, 이기창 지음
'NLP' 카테고리의 다른 글
| Sentence Embedding Summary (0) | 2020.08.23 |
|---|---|
| Word Embedding Summary (0) | 2020.08.23 |
| konlpy 형태소 분석기 성능 비교 (0) | 2020.08.17 |
| 임베딩에 쓰이는 세가지 통계 정보 (0) | 2020.07.15 |
| 1.1 임베딩(embedding) (0) | 2020.07.15 |

