
opentutorials.org/course/4570/28976
두번째 딥러닝 - 보스턴 집값 예측 - 생활코딩
수업소개 보스턴 집값을 예측하는 딥러닝 모델을 텐서플로우를 이용하여 만들어 보고, 모델을 구성하는 퍼셉트론에 대해 이해합니다. 강의 수식과 퍼셉트론 실습 소스코드 colab | backend.
opentutorials.org
보스턴 집값 예측(강의)
|
온도 |
판매량 |
|
20 |
40 |
|
21 |
42 |
|
22 |
44 |
|
23 |
46 |
y = 2x
이전 시간에서 우리가 찾은 데이터와 데이터의 관계입니다. 우리는 뉴런 1개로 동작하는 모델을 만들었습니다.
우리는 이번시간에 다음과 같은 복잡한 공식을 스스로 학습하는 모델을 만들어 보도록 하겠습니다.

복잡해 보이고 어려울 것 같나요?? 하지만 우리는 이 복잡한 공식을 배우기 위해 이미 앞에서 많은 내용을 학습했습니다!! 확인해보도록 하겠습니다.
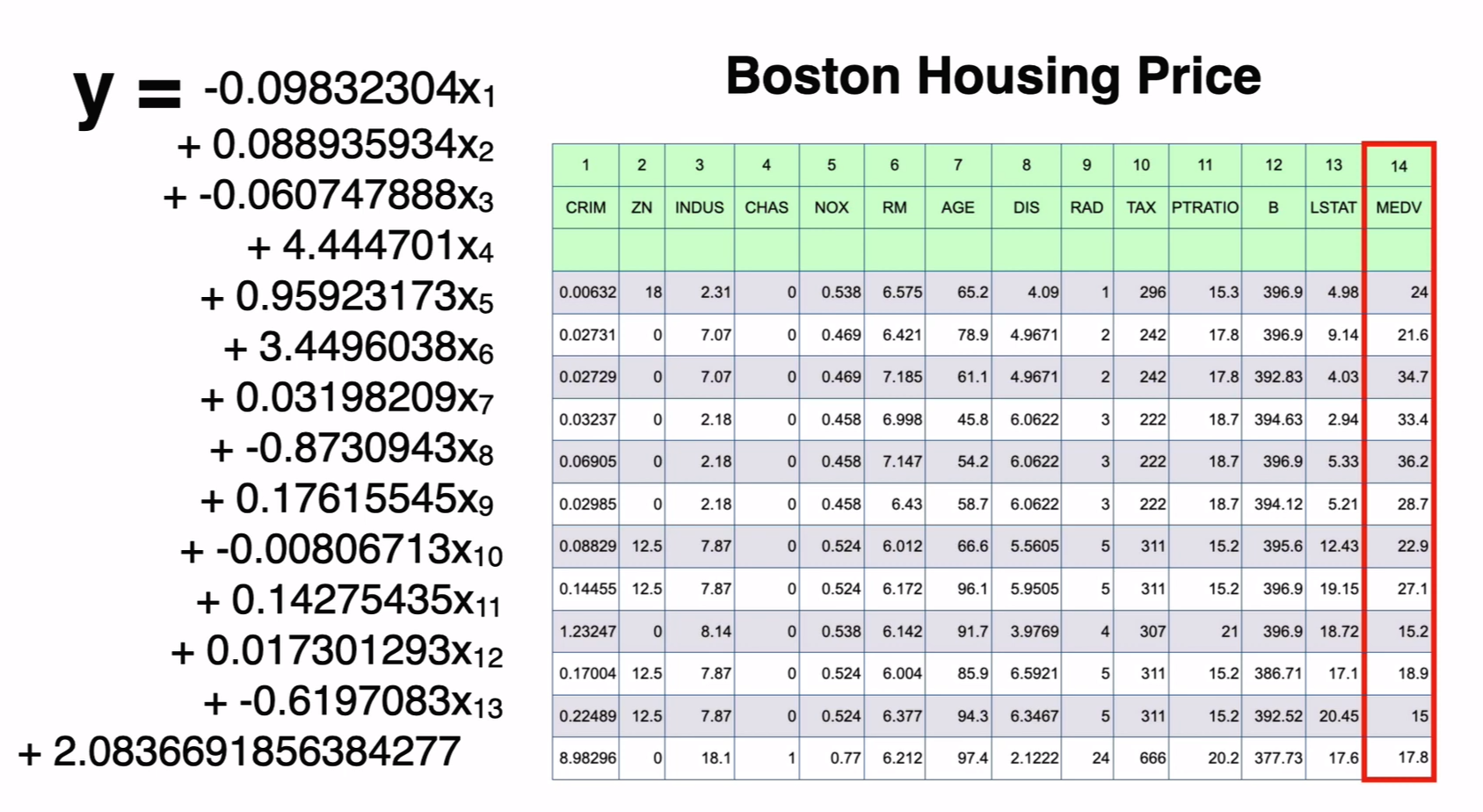
지금부터 우리는 보스턴의 주택 정책을 관리하는 공무원이라고 생각을 해보겠습니다. 주택 가격 현황을 살펴보기 위해 다음가 같은 데이터를 받았습니다.
각각의 행하나는 타운 1개를 의미합니다. 열은 각 타운의 특성들을 의미합니다. 이 중 가장 중요한 열은 MEDV라는 열입니다. MEDV는 해당 타운에 있는 주택들 가격의 중앙값을 의미합니다.
여기서 잠깐 중앙값에 대해 알아보도록 하겠습니다.

이렇게 값을 작은 값부터 정렬을 한 후 가장 가운데 있는 값을 우리는 중앙값이라고 합니다. 중앙값과 비슷하게 평균값이라는 것이 있는데 이 두개의 값은 모두 집단을 대표하는 값으로 사용이 됩니다.
일반적으로는 평균이 집단을 대표하는 값으로 아주 좋은 지표입니다. 하지만 어떠한 경우에는 평균이 집단을 대표하는 값으로 나타내기에 좋지 않은 경우도 있습니다.
예를들어 뉴스에 평균연봉이라고 하는 기사를 보면 실제 우리가 느끼는 연봉과 거리가 멀다고 생각하게 됩니다. 그 이유는 연봉이 매우 높은 사람들에 의해 평균에 영향을 미치기 때문에 발생하는 현상입니다. 이렇게 전체 집단보다 상이하게 값이 낮거나 높아 평균에 대표성을 무너지게 하는 이러한 값들을 이상치라고 합니다.
이를 위해 평균을 대신하여 사용하는 값이 바로 중앙값입니다.

변수들이 의미하는 바는 다음과 같습니다. 여기서 1~13까지가 독립변수입니다. 왼쪽 공식이 바로 이 독립변수들이 어떻게 종속변수에 영향을 미치는지 보여주는 공식이 바로 왼쪽 공식입니다.

이렇게 우리는 X에 해당하는 값들을 대입하며 계산을 해주면 집값을 얻을 수 있습니다. 실제값이랑은 차이가 있지만 어느정도 비슷한 값을 얻을 수 있습니다. 학습을 잘 시키면 더욱 정확한 값을 만들 수 있겠죠?
보스턴 집값 예측(수식과 퍼셉트론)

다음은 우리가 모델을 사용하기 위한 전체적인 구조입니다. 레모네이드 예제와 어떤 차이가 있는지 생각해보면서 살펴보도록 하겠습니다.
먼저, 독립변수와 종속 변수를 분리하는 과정에서 데이터가 달라졌기 때문에 들어가는 값들이 달라진것을 알 수 있습니다.
다음으로 #2를 보시면 X, Y에서 독립변수와 종속변수 수에 따라서 숫자가 달라진것을 알 수 있습니다.
이 두가지를 제외하고는 레모네이드 예제와 동일한 방식으로 학습을 하고 있습니다.
#2 과정을 조금 더 자세하게 살펴보고 그 구조를 이해보도록 하겠습니다.

우리는 독립변수가 13개이고 종속변수가 1개 이기 때문에 13과 1을 넣어주었습니다. 이를 풀이하자면 13개의 입력을 받는 입력층, 1개의 출력을 만드는 출력층을 구성한다는 의미입니다. 정리하자면 13개의 입력으로 부터 1개의 출력을 만들어 내는 구조!! 입니다. 그 표현이 바로 위의 수식입니다.
두번째 줄의 Dense는 이 수식을 만들고 컴퓨터는 학습 과정에서 입력 데이터를 보고 이 수식의 W와 b를 찾는 것입니다.
뉴런은 실제 두뇌 세포 이름이고 인공신경망에서 뉴런 역할을 하는 것이 바로 이 모형과 수식입나다. 이 모형에는 퍼셉트론이라는 이름이 있고 w는 가중치 b는 편향(바이어스)라고 말합니다.
예를들어 데이터가 독립변수 12개, 종속변수 2개라고 가정을 하면 다음과 같이 모델 구조를 구성하게 됩니다.

하나의 결과를 만드는 데에 수식 1개를 필요로 하는데 지금 종속변수가 2개이기 때문에 우리는 수식 2개가 필요 합니다. 위에 그림은 퍼셉트론 2개가 병렬로 된 구조입니다.
위 구조를 보면 우리는 첫번째 수식에서 가중치 12개, 바이어스 1개 두번째 수식에서 가중치 12개, 바이어스 1개 총 26개의 숫자를 찾아야 하는 것입니다.
이번 수업에서는 모델의 구조를 깊게 알아보는 시간을 가졌습니다. 방금 배웠던 구조를 떠올리면서 기억을 하도록 합시다.
실습은 다음 github 사이트에서 확인할 수 있습니다.
github.com/jaaaamj0711/Machine_learning_yahac/blob/main/boston.ipynb
jaaaamj0711/Machine_learning_yahac
구글과 생활코딩이 함께하는 머신러닝 야학 2기 입니다. Contribute to jaaaamj0711/Machine_learning_yahac development by creating an account on GitHub.
github.com
'머신러닝 야학 2기' 카테고리의 다른 글
| [머신러닝 야학 2기] 4일차 - 아이리스 품종 분류 (0) | 2021.01.07 |
|---|---|
| [머신러닝 야학 2기] 3일차 - 학습의 실제 (0) | 2021.01.06 |
| [머신러닝 야학 2기] 2일차 - 레모네이드 판매 예측 (0) | 2021.01.05 |
| [머신러닝 야학 2기] 2일차 - 표를 다루는 도구 '판다스' (0) | 2021.01.05 |
| [머신러닝 야학 2기] 1일차 - 지도학습의 빅픽쳐 (0) | 2021.01.04 |



