2-2 Stratified K 폴드
- Stratified K 폴드는 원본 데이터의 레이블 분포를 먼저 고려한 뒤 이 분포와 동일하게 학습과 검증 데이터 세트를 분해하여 줍니다.
- Stratified K 폴드는 불균형한 분포를 가진 레이블들을 위한 방식입니다.
불균형한 분포: 특정 레이블 값이 특이하게 많거나 매우 적어서 값의 분포가 한쪽으로 치우치는 것을 말한다.
- 먼저 붓꽃 데이터의 레이블 값들의 분포도를 확인해 보도록 하겠습니다.
In
import pandas as pd
iris=load_iris()
iris_df=pd.DataFrame(data=iris_data,columns=iris.feature_names)
iris_df['label']=iris.target
iris_df['label'].value_counts()Out
2 50
1 50
0 50iris 원본 데이터는 50:50:50의 비율로 구성되어 있는 것을 확인하였습니다.
- 다음은 StratifiedKFold를 상ㅇ해서 학습/검증 레이블 데이터의 분포도를 확인해 보겠습니다.
In
from sklearn.model_selection import StratifiedKFold
skf=StratifiedKFold(n_splits=3) #폴드 세트는 3개로 설정
for train_index, test_index in skf.split(iris_df, iris_df['label']):
n_iter += 1
label_train= iris_df['label'].iloc[train_index]
label_test= iris_df['label'].iloc[test_index]
print('## 교차 검증 : {0}'.format(n_iter))
print('학습 레이블 데이터 분포:\n', label_train.value_counts())
print('검증 레이블 데이터 분포:\n', label_test.value_counts())Out
## 교차 검증 : 6
학습 레이블 데이터 분포:
2 33
1 33
0 33
Name: label, dtype: int64
검증 레이블 데이터 분포:
2 17
1 17
0 17
Name: label, dtype: int64
## 교차 검증 : 7
학습 레이블 데이터 분포:
2 33
1 33
0 33
Name: label, dtype: int64
검증 레이블 데이터 분포:
2 17
1 17
0 17
Name: label, dtype: int64
## 교차 검증 : 8
학습 레이블 데이터 분포:
2 34
1 34
0 34
Name: label, dtype: int64
검증 레이블 데이터 분포:
2 16
1 16
0 16결과를 보면 학습 레이블과 검증 레이블 데이터 값의 분포도가 동일하게 나온것을 알 수 있습니다.
2-2 cross_val_score()
- 교차 검증을 좀 더 편리하게 수행할 수 있도록 도와주는 함수입니다.
cross_val_score(estimator, X, y=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None,
pre_dispatch='2*n_jobs')
estimatot, X, y, scoring, cv가 중요한 파라미터입니다.
- estimator: 분류 알고리즘 클래스 또는 회귀 알고리즘 클래스를 의미합니다.
- X: 피처 데이터 세트
- y: 레이블 데이트 세트
- scoring: dPcmr tjdsmd vudrk wlvy
- cv: 교차 검증 폴드 수
- 다음 예제를 통해서 cross_val_score() 사용법을 알아보도록 하겠습니다.
In
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score, cross_validate
iris_data=load_iris()
dt_clf=DecisionTreeClassifier(random_state=156)
data=iris_data.data
label=iris_data.targetscores=cross_val_score(dt_clf,data,label,scoring='accuracy',cv=3)
print('교차 검증별 정확도:',np.round(scores,4))
print('평균 검증 정확도',np.round(np.mean(scores),4))Out
교차 검증별 정확도: [0.9804 0.9216 0.9792]
평균 검증 정확도 0.9604
2-2 GridSearchCV
- 하이퍼 파라미터를 순차적으로 입력하면서 편리하게 최적의 파라미터를 도출할 수 있는 방안을 제공해주는 함수입니다.
하이퍼 파리미터: 머신러닝 알고리즘을 구성하는 주요 구성요소로, 이 값을 어떻게 조정하는지에 따라 예측 성능이 낮아지고 높아질 수 있습니다.
- GridSearchCV 는 교차 검증을 기반으로 하이퍼 파라미터의 최적 값을 찾아 줍니다.
- 수행시간이 상대적으로 오래 걸립니다.
수행 과정을 예시로 표현하면 다음과 같습니다.
| 번호 | max_depth | min_smples_split |
| 1 | 1 | 2 |
| 2 | 1 | 3 |
| 3 | 2 | 2 |
| 4 | 2 | 3 |
위 예시의 경우 4회에 걸쳐 하이퍼 파리미터를 변경하면서 교차 검증 데이터을 수행하게 됩니다.
- 다음은 예제를 통해서 GridSearchCV 사용법을 알아보도록 하겠습니다.
In
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=121)먼저 train_test_split()를 사용해서 학습 데이터와 테스트 데이터를 분리하여 줍니다.
dtree = DecisionTreeClassifier()
parameters={'max_depth':[1,2,3],'min_samples_split':[2,3]}결정 트리 알고리즘을 사용해서 구현을 해보겠습니다. 파라미터는 DecisionTreeClassifier()에서 중요한 max_depth()와 min_samples_split를 사용하도록 하겠습니다.
import pandas as pd
grid_dtree = GridSearchCV(dtree,param_grid=parameters,cv=3,refit=True)
grid_dtree.fit(x_train,y_train)학습 데이터 세트를 GridSearchCV 객체의 학습 데이터 세트 메서드에 인자로 입력하여 줍니다.
Out
GridSearchCV(cv=3, error_score='raise-deprecating',
estimator=DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best'),
fit_params=None, iid='warn', n_jobs=None,
param_grid={'max_depth': [1, 2, 3], 'min_samples_split': [2, 3]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)결과가 다음과 같이 출력이 되었는데 보기 쉽게 데이트 프레임으로 변환하여 결과를 해석해 보도록 하겠습니다.
In
scores_df=pd.DataFrame(grid_dtree.cv_results_)
scores_df[['params','mean_test_score','rank_test_score',
'split0_test_score','split1_test_score','split2_test_score']]Out
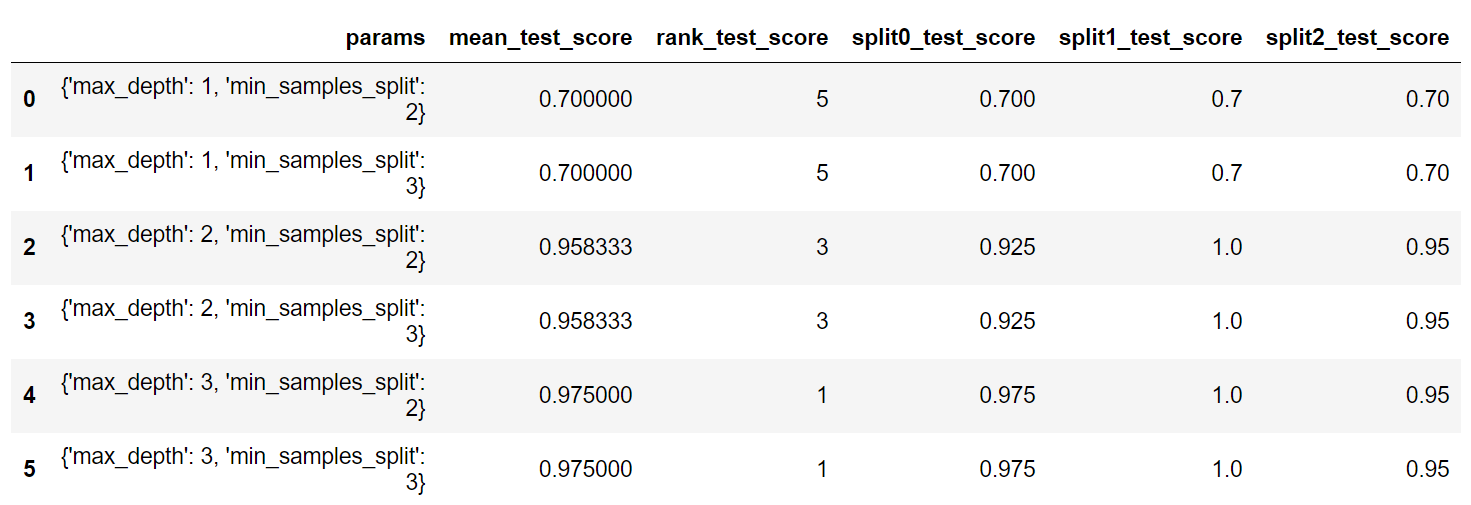
출력 결과를 봤을때 rank_test_score값이 1위인 4,5 가 예측 성능이 가장 높은 것을 확인할 수 있습니다.
In
print('최적 파라미터:',grid_dtree.best_params_)
print('최고 정확도:{0:.4f}'.format(grid_dtree.best_score_))Out
최적 파라미터: {'max_depth': 3, 'min_samples_split': 2}
최고 정확도:0.9750다음과 같이 최적 파라미터와 정확도를 출력 할 수 도 있습니다.
Reference
'Machine Learning' 카테고리의 다른 글
| 사이킷런으로 시작하는 머신러닝 - 데이터 전처리(피처 스케일링)- (0) | 2020.04.10 |
|---|---|
| 사이킷런으로 시작하는 머신러닝 - 데이터 전처리(데이터 인코딩)- (0) | 2020.04.10 |
| 사이킷런으로 시작하는 머신러닝 - Model Selection 모듈(1)- (0) | 2020.04.09 |
| 사이킷런으로 시작하는 머신러닝 - 사이킷런의 기반 프레임워크 익히기- (1) | 2020.04.09 |
| 데이터프레임(DataFrame) 다루기 ◑_◐ (0) | 2020.04.07 |



