데이터 전처리
- 사이킷런의 ML 알고리즘을 적용하기 전에 데이터에 대해 미리 처리해야 될 부분들이 있습니다.
- 결손값, 즉 NAN, NULL값은 다른 값으로 변환해야 합니다.
NULL값은 어떻게 처리해야 하는지는 데이터에 따라 달라지게 됩니다. 예를들어 NULL값이 얼마 되지 않는다면 피처의 평균값으로 간단히 대체를 할 수 있습니다. 하지만 만약 NULL 값이 대부분을 차지한다면 NULL 값을 버리는 것이 더 좋습니다. 따라서 NULL값을 처리할때는 데이터를 상세하게 검토하고 고민하여 어떠한 값으로 대체할지 잘 선정을 해주어야 합니다.
-
문자열 값은 숫자형으로 변환해주어야 합니다.
사이킷런의 ML 알고리즘은 문자열 값을 입력 값으로 지원하지 않습니다. 그래서 문자열 값들은 인코딩 과정을 거쳐 숫자형으로 변환을 시켜줘야 합니다. 문자열 피처는 카테고리형 피처, 텍스트형 피처가 있습니다.
1. 데이터 인코딩
- 대표적인 인코딩 방식은 레이블 인코딩(Label encodig)과 원-핫 인코딩(One Hot encoding)이 있습니다.
1-1 레이블 인코딩(Label encoding)
- 레이블 인코딩은 카테고리 피처들을 코드형 숫자 값으로 변환시켜주는 방법입니다. 예를 들어 과일 데이터의 구분이 사과, 바나나, 자두, 포도, 망고, 키위, 참외 값으로 구성되어 있다고 했을때 사과:1, 바나나:2, 자두:3, 포도:4, 망고:5, 키위:6, 참외:7 과 같이 숫자형 값으로 변환하여 주는 것입니다. '01', '02' 와 같은 값들도 문자열 이므로 숫자형 값으로 변환해 주는것을 주의!! 해주어야 합니다.
- 레이블 인코딩은 LabelEncoder() 함수를 사용합니다.
In
from sklearn.preprocessing import LabelEncoder
items = ['사과', '바나나', '자두', '포도', '망고', '망고','키위','키위']
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값:',labels)fit()과 transform()을 사용해서 레이블 인코딩을 수행시켜 줍니다.
Out
인코딩 변환값: [2 1 3 5 0 0 4 4]숫자형 값으로 인코딩 됨을 확인하였습니다.
In
print('디코딩 원본값:',encoder.inverse_transform([4,5,2,0,1,1,3,3]))다음과 같이 inverse_transform() 함수를 사용해서 인코딩된 값을 다시 디코딩할 수 있습니다.
Out
디코딩 원본값: ['키위' '포도' '사과' '망고' '바나나' '바나나' '자두' '자두']
이렇게 레이블 인코딩은 문자열 값을 숫자형 카테고리 값으로 변환을 시켜줍니다. 하지만 몇몇 ML 알고리즘에서는 이를 적용할 경우에 예측 성능이 떨어지는 경우가 있습니다. 왜 그럴까요??
그 이유는 숫자 값의 경우 크고 작음에 대한 특성이 작용되기 때문입니다.
쉽게 설명하자면 사과:1, 바나나:2의 경우 1보다 2가 더 큰 값이기 때문에 특정 ML 알고리즘에서는 가중치를 2로 더 많이 부여하게 될 가능성이 발생합니다. 하지만 사과와 바나나의 숫자 변환 값은 숫자 값에 따른 중요도로 인식하면 안됩니다. 이러한 문제를 해결하기 위해 나온 인코딩 방식이 바로 원-핫 인코딩입니다.
1-2 원-핫 인코딩(One-Hot encoding)
- 원- 핫 인코딩은 피처 값의 유형에 따라 새로운 피처를 추가해서 고유 값에 해당하는 컬럼에만 1을 표시하고 나머지 컬럼에는 0을 표시하는 방법입니다.
이해하기 쉽게 그림으로 표현하면 아래와 같습니다.
| 과일 분류 |
| 사과 |
| 바나나 |
| 자두 |
| 포도 |
| 망고 |
| 망고 |
| 키위 |
| 키위 |
↓
| 사과 | 바나나 | 자두 | 포도 | 망고 | 키위 |
| 1 | 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 1 |
OneHotEncoder()로 변환하기 전에 1) 모든 문자열 값을 숫자형 값으로 변환을 해주어야하고, 2) 입력 값으로 2차원 데이터가 필요합니다.
In
from sklearn.preprocessing import LabelEncoder
import numpy as np
items = ['사과', '바나나', '자두', '포도', '망고', '망고','키위','키위']
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)LabelEncoder()를 사용해서 숫자 값으로 변환을 시켜줍니다.
labels=labels.reshape(-1,1)2차원 데이터로 변환하여 줍니다.
oh_encod = OneHotEncoder()
oh_encod.fit(labels)
oh_encod = oh_encod.transform(labels)
print('원-핫 인코딩 데이터')
print(oh_encod.toarray())OneHotEncoder()를 이용해 변환하여 줍니다.
Out
원-핫 인코딩 데이터
[[0. 0. 1. 0. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 1.]
[1. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1. 0.]]
-
판다스에서는 원-핫 인코딩을 더 쉽게 지원해주는 get_dummies() 함수가 있습니다.
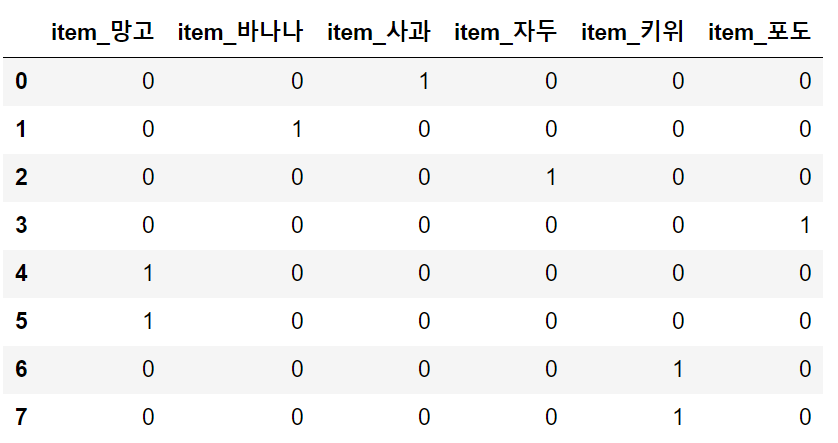
In
import pandas as pd
df=pd.DataFrame({'item':['사과', '바나나', '자두', '포도', '망고', '망고' ,'키위','키위']})
pd.get_dummies(df)Out
Reference
'Machine Learning' 카테고리의 다른 글
| 결정 트리(Decision Tree) (0) | 2020.04.16 |
|---|---|
| 사이킷런으로 시작하는 머신러닝 - 데이터 전처리(피처 스케일링)- (0) | 2020.04.10 |
| 사이킷런으로 시작하는 머신러닝 - Model Selection 모듈(2)- (0) | 2020.04.09 |
| 사이킷런으로 시작하는 머신러닝 - Model Selection 모듈(1)- (0) | 2020.04.09 |
| 사이킷런으로 시작하는 머신러닝 - 사이킷런의 기반 프레임워크 익히기- (1) | 2020.04.09 |



