배깅(bagging)의 개념을 다시 살펴보면 같은 알고리즘으로 여러개의 분류기를 만드는 알고리즘입니다. 배깅의 대표적인 알고리즘은 랜덤 포레스트(Random forest)가 있습니다.
랜덤 포레스트(Random forest)란?
랜덤 포레스트는 결정 트리를 기반으로 하는 알고리즘입니다. 랜덤 포레스트는 여러 개의 결정 트리 분류기가 배깅을 기반으로 각자의 데이터를 샘플링 하여 학습을 수행한 후에 최종적으로 보팅을 통해 예측 결정을 하게 됩니다.
랜덤 포레스트는 부트스트래핑(bootstrapping) 방식으로 분할 합니다. 그렇기 때문에 중첩되게 샘플링이 됩니다.
부트스트래핑(bootstrapping): 여러개의 데이터 세트를 중첩되게 분리하는 방식
▷ 사이킷런에서는 RandomForestClassifier 클래스를 통해서 랜덤 포레스트 기반의 분류를 지원합니다.
-
결정 트리에서 사용했던 사용자 행동 인식 데이터 세트를 사용해서 예측을 해보겠습니다.
In
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings.filterwarnings('ignore')필요한 모듈들을 로딩하여 줍니다.
x_train, x_test, y_train, y_test = human_dataset()
rf = RandomForestClassifier(random_state=0)
rf.fit(x_train,y_train)
pred = rf.predict(x_test)
accuracy = accuracy_score(y_test,pred)재 수행할때마다 동일한 예측 결과를 위해서 random_state를 0으로 설정하였습니다.
accuracy = accuracy_score(y_test,pred)
Out

정확도가 약 91.08% 나왔습니다.
랜덤 포레스트 하이퍼 파라미터
트리 기반의 알고리즘의 단점은 하이퍼 파리미터가 너무 많다는 것입니다. 이로 인해 튜닝을 위한 시간이 많이 필요하게 됩니다. 시간을 많이 투자함에도 불구하고 예측 성능이 크게 좋아지는 경우가 없습니다...
▷ 랜덤 포레스트의 하이퍼 파라미터에 대해서 알아보겠습니다.
-
n_estimatos: 결정 트리의 개수를 의미합니다. 디폴트값은 10개입니다. 계속 증가시킨다고 해서 성능이 무조건 향상되는 것은 아닙니다.(개수의 수가 늘어날수록 수행 시간이 오래 걸린다는 것을 감안하여야 합니다.)
- max_features: 결정 트리의 max_features 파라미터와 동일합니다. 랜덤 포레스트에서는 디폴트 값이 'auto'입니다. auto: sqrt(전체 피처 개수)
- 결정 트리와 동일하게 과적합 개선을 위해서 max_depth와 min_samples_leaf가 사용이 됩니다.
-
GridSearchCV를 사용해서 랜덤 포레스트의 하이퍼 파리미터를 튜닝해보도록 하겠습니다.
시간 절약을 위해서 n_estimators=100, CV=2로 설정을 하도록 하겠습니다.
In
from sklearn.model_selection import GridSearchCV
params ={
'n_estimators':[100],
'max_depth':[6,8,10,12],
'min_samples_leaf':[8,12,18],
'min_samples_split':[8,16,20]
}rf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(x_train,y_train)

최고 하이퍼 파라미터 n_estimators: 100, max_depth': 10, min_samples_leaf: 8, min_samples_split: 8일때 최고 예측 정확도가 약 91.66%로 나왔습니다. 이 하이퍼 파라미터를 가지고 테스트 데이터 세트에서 예측을 해보겠습니다.
In
rf_1=RandomForestClassifier(n_estimators=300, max_depth=10, min_samples_leaf=8,
min_samples_split=8, random_state=0)
rf_1.fit(x_train,y_train)
pred=rf_1.predict(x_test)
print('예측 정확도:{0:.4f}'.format(accuracy_score(y_test,pred)))Out

테스트 데이터 세트에서는 예측 정확도 수치가 약 91.65%정도 나왔습니다.
▷ 랜덤 포레스트에서도 결정 트리와 동일하게 feature_importances_ 속성을 이용하여 피처의 중요도를 알 수 있습니다. 피처 중요도를 막대그래프를 사용하여 시각화해 보겠습니다.
In
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline필요한 모듈을 로딩하여 줍니다.
importances_values = rf.feature_importances_
importances = pd.Series(importances_values, index=x_train.columns)
top20 = importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8, 6))
plt.title('Feature importances Top 20')
sns.barplot(x = top20, y = top20.index)
plt.show()
Out
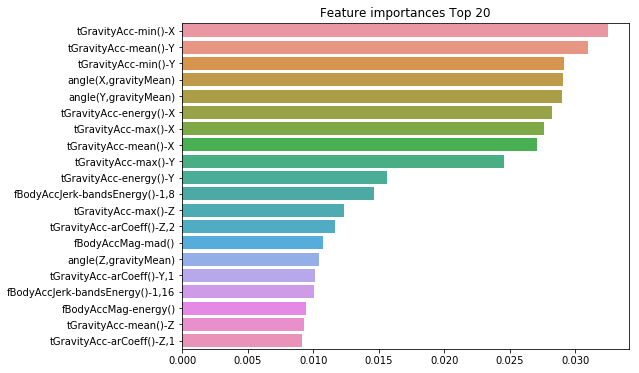
※ tGravityAcc-min()-X, tGravityAcc-mean()-Y, tGravityAcc-min()-Y 등이 높은 피처 중요도로 나왔습니다.
Reference
'Machine Learning' 카테고리의 다른 글
| XGBoost(eXtra Gradient Boost) (0) | 2020.04.26 |
|---|---|
| GBM(Gradient Boosting Machine) (1) | 2020.04.26 |
| 앙!상블 (0) | 2020.04.21 |
| 결정 트리 실습(사용자 행동 인식 데이터) (0) | 2020.04.19 |
| 결정 트리(Decision Tree) (0) | 2020.04.16 |


